
Что такое файл robots.txt? С помощью этого файла, вы сообщаете поисковым роботам, о том, какие страницы нужно индексировать, а какие нет. Из этой статьи вы узнаете, как его правильно использовать. Начнем с краткого
Как использовать файл robots.txt
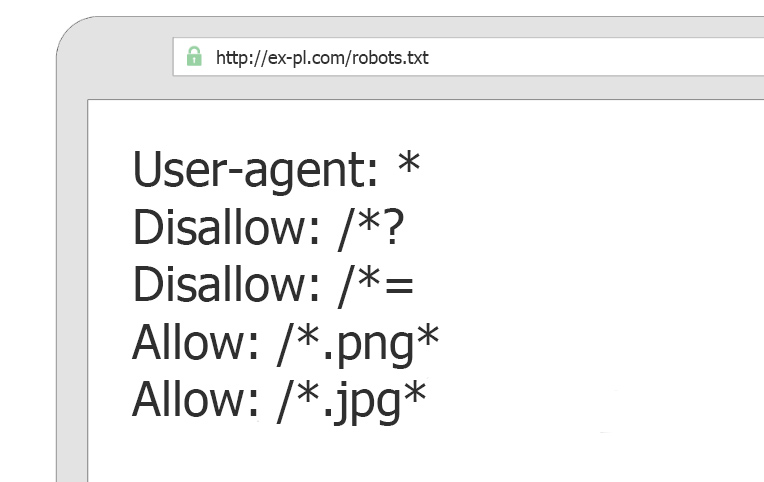
Что такое файл robots.txt? С помощью этого файла, вы сообщаете поисковым роботам, о том, какие страницы нужно индексировать, а какие нет. Из этой статьи вы узнаете, как его правильно использовать. Начнем с краткого описания:
Robots.txt – текстовой файл, размещенный на сервере (в корне сайта), который сообщает поисковым ботам, что нужно индексировать, а что нет.
Типичная конфигурация файла robots.txt, ниже я объясню, что это значит.
User-agent: *<br /> Disallow:<br /> User-agent: *<br /> Disallow: /<br /> User-agent: *<br /> Disallow: /folder/<br /> User-agent: *<br /> Disallow: /page.html
Зачем нам знать о файле robots.txt?
- Незнание и непонимание того, как работает файл robots.txt, может иметь негативное влияние на рейтинг вашего сайта.
- Файл robots.txt контролирует то, как поисковые алгоритмы индексируют ваш сайт.
Алгоритм работы
Первое, что сделает поисковый бот, когда посетит ваш сайт – это обращение к файлу robots.txt. С какой целью? Робот хочет знать, имеет ли полномочия, проиндексировать сайт или ту или иную страницу сайта. Если нет явного запрета на обход страниц, то робот продолжает свою работу. Если существуют запреты, то робот покинет сайт. Поэтому, если вы хотите использовать какие-либо инструкции для поисковых роботов, то файл robots.txt – это тот самый инструмент.
Внимание! Существуют два важных нюанса, которые вебмастер должен проверить, если речь идет о файле robots.txt:
- Определить существует ли этот файл;
- Убедиться, что он не вредит индексации сайта.
Как проверить, что robots.txt существует и не мешает индексации?
Проверить существует ли такой файл можно с помощью любого веб-браузера. Файл должен быть размещен в корневой папке сайта. Достаточно просто в адресную строку ввести site.ru/robots.txt (site.ru заменив вашим доменным именем) и отобразиться содержимое этого файла. Если такого файла не существует или он пуст, то вы увидите просто белый фон или 404 ошибку.
Проверить не мешают ли директивы файла robots.txt можно через Яндекс.Вебмастер во вкладке "Инструменты -> Анализ robots.txt.
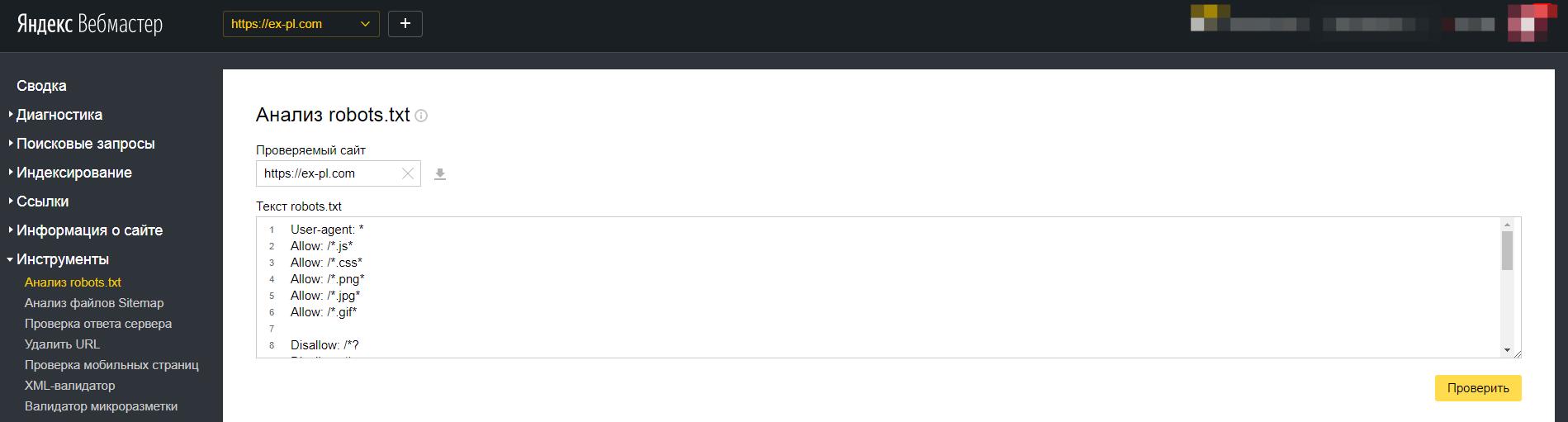
В поле "Разрешены ли URL?" достаточно вставить адреса ваших страниц и нажать "проверить". Результат будет ниже
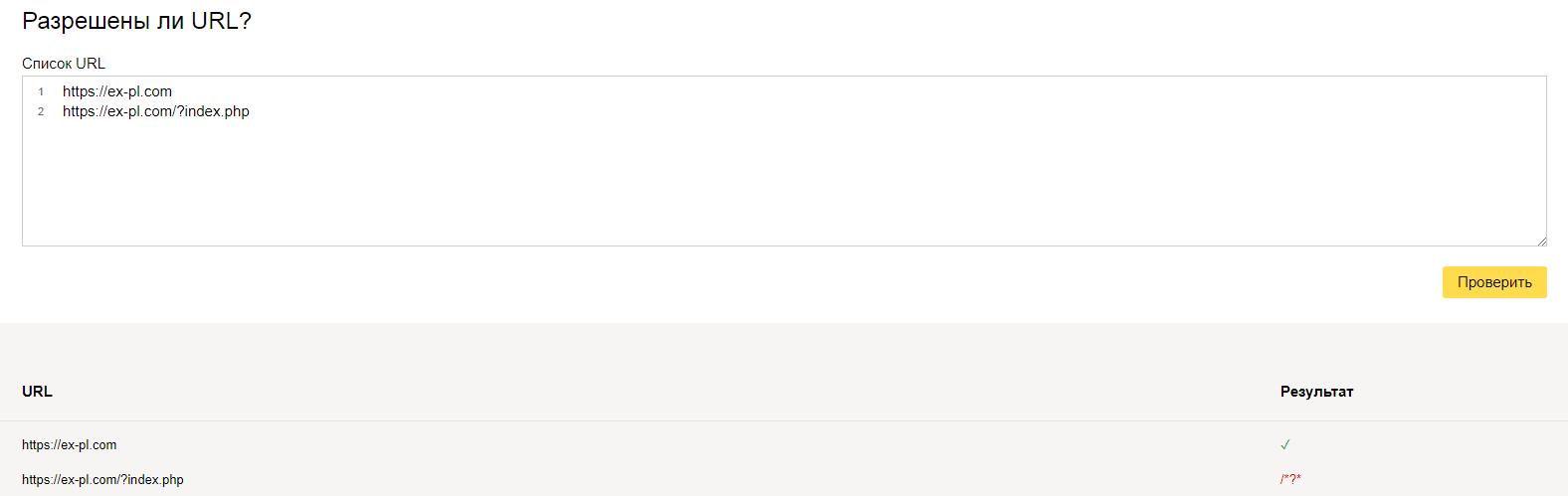
Аналогичную процедуру можно проделать и в Google Search Console.
Зачем нам нужен файл robots.txt?
Итак, мы знаем, где искать файл robots.txt и то, что он нужен, но зачем он нужен, какие конкретные причины?
- На сайте есть страницы, которые вы не хотите показывать поисковым системам;
- Необходимо, чтобы доступ к сайту имели только определенные роботы, например, сканеры Google и Яндекс;
- Вы создаете новый раздел и планируете новую структуру. Для того, чтобы ваши «тесты» не попадали в поисковую выдачу, лучше закрыть эти разделы от индексации;
- У вас многожество дублей страниц и вы хотите исключить эти дубли из поиска.
Как создать файл robots.txt?
Очень просто. Robots.txt – простой текстовой файл. Достаточно создать такой файл у себя на компьютере и закачать его на сайт через FTP-клиент, либо, если платформа позволяет это сделать, то создать такой файл прямо на хостинге.
Инструкции robots.txt – тут уже сложнее
Теперь необходимо разобраться, как этот файл правильно использовать.
User-agent
Синтаксис User-agent определяет в отношении каких ботов действуют правила. Есть два способа это сделать:
- User-agent: * - такой способ говорит, что, любой робот должен придерживаться следующих «правил».
- User-agent: GoogleBot – этот способ говорит, что данный «правила» касаются только и исключительно для робота GoogleBot.
Disallow
Инструкция «Disallow» - запрещает роботам индексировать те или иные элементы (файлы, страницы, папки, изображения). Таким образом, если вы не хотите, чтобы содержимое папки «temp» не было проиндексировано, нужно указать это в файле robots.txt следующим образом:
User-agent: *<br /> Disallow: /temp
Allow
Все что не закрыто по-умолчанию - открыто. Поэтому «allow» часто используется в сочетании с «disallow». Например.
В предыдущем примере мы закрыли от индексации папку temp, однако через некоторое время мы решили, что мы хотим открыть доступ роботам к файлу my.docx, который находиться в папке temp, но только к нему, а не к другим файлам в это папке. Запись allow позволяет нам предоставить доступ к этому файлу (или группе файлов\папок), таким образом:
User-agent: *<br /> Disallow: /temp<br /> Allow: /temp/my.docx
Что еще должно быть в файле robots.txt?
Кроме деректив поисковым роботам о том, что нужно или не нужно индексировать, в файл robots.txt желательно прописать путь до карты сайты, делается это следующим образом:
Sitemap: https://ex-pl.com/sitemap.xml
Как проверить, что файл robots.txt работает правильно?
Правильность вашего файла вы можете проверить в Яндекс.Вебмастере или Google Search Console.
Важные замечания
Закрытие страниц, папок, файлов от поисковых роботов через файл robots.txt не гарантирует не попадания этих элементов в поисковую выдачу. Все же директивы в этом файле имеют рекомендательный характер для ботов и они могут воспользоваться этими рекомендациями, а могут не воспользоваться. Для того, чтобы на 100% исключить из индекса ту или иную страницу, можно воспользоваться тегами noindex\nofollow.
Примеры robots.txt
Пример 1
User-agent: *<br /> Disallow:
Все роботы могут посещать и индексировать все файлы и страницы сайта.
Пример 2
User-agent: *<br /> Disallow: /
Закрыть сайт от индексации через robots.txt полностью. Это значит, что ваш сайт не будет отображаться в результатах поиска.
Пример 3
User-agent: *<br /> Disallow: /cgi/<br /> Disallow: /private/<br /> Disallow: /tmp/
Ни один из роботов не будет индексировать папки: cgi, private, tmp.
Пример 4
User-agent: Googlebot-Image<br /> Disallow: /photos/
Картиночному боту Google запрещен доступ к папке photos.
Пример 5
User-agent: *<br /> Disallow: /directory/file.html
Все роботам запрещено индексировать файл file.html в папке directory.
Пример 6
User-agent: WebStripper<br /> Disallow: /
User-agent: WebCopier<br /> Disallow: /
User-agent: TeleportPro<br /> Disallow: /
User-agent: HTTrack<br /> Disallow: /
User-agent: wget<br /> Disallow: /
Данные директивы запрещают некоторым программам доступ к сайту.






Сроки и условия
Подписаться
Отчёт