
Словосочетания «дубликаты страниц» или «дубликат контента» запали в сердца многих веб-мастеров и SEO-оптимизаторов
Какие бывают дубликаты страниц и как от них избавиться
 Из многочисленных проблем в SEO, дубли страниц на сайте одна из проблем, которую решить проще всего.
Из многочисленных проблем в SEO, дубли страниц на сайте одна из проблем, которую решить проще всего.
Словосочетания «дубли страниц» или «дубликат контента» запали в сердца многих веб-мастеров и SEO-оптимизаторов. Но правда в том, что не каждый дубликат контента является негативным фактором при оптимизации сайта, а вернее сказать, существуют разные типы дубликатов и они не равны!
Почему нужно обратить внимание на дубли страниц?
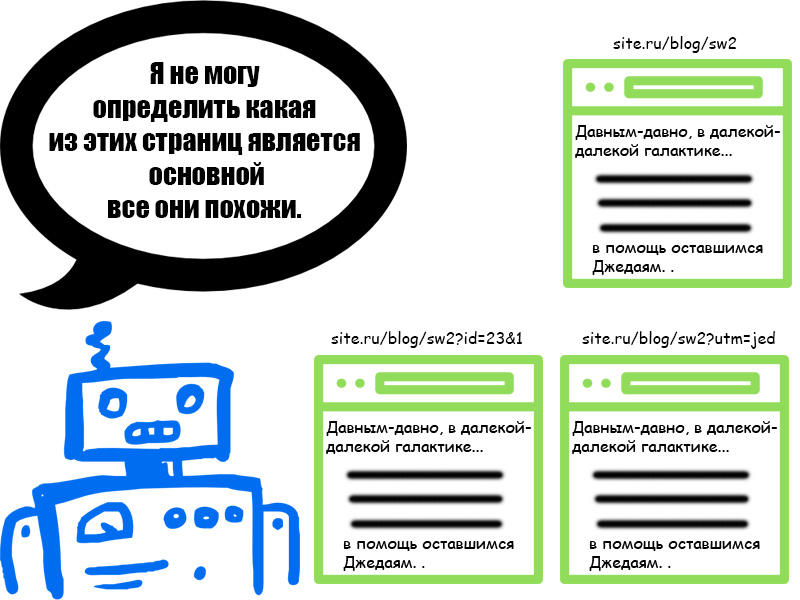
Дубли страниц с точки зрения поисковых систем
- Они не знают какую страницу следует индексировать, а какую страницу выкидывать из индекса. Вследствие чего, не редки такие случаи, когда то одна страница влетает в поиск, а остальные вылетают, то наоборот. Как следствие, позиции для этой страницы могут существенно изменятся.
- Они не знают какой странице передавать траст и вес, а вернее сказать, они не могут определить, каким образом эти параметры должны передаваться, для каждой страницы, в отдельности или только для одной из них.
Дубли страниц с точки зрения владельца сайта
- Поисковые системы крайне редко ставят в выдачу две страницы с одинаковым содержимым (дубли страницы на сайте), поэтому они вынуждены самостоятельно выбирать, какую из страниц нужно показывать в результатах поиска. Это разбавляет видимость каждого из документов. Как следствие потеря трафика.
- На разные адреса страниц могут быть ссылки внутри сайта или из внешних источников, а поскольку ссылочный вес является одним из факторов ранжирования, то очевидна потеря "веса" остальных страниц.
О неуникальном контенте
Поскольку контент является ключевым элементом хорошего SEO, многие пытались манипулировать результатом поисковой выдачи с помощью старого доброго метода “копировать и вставить”, т.е. забирали контент на свой сайт с других сайтов. Поисковые системы, как правило, наказывают за такой метод, поэтому он должен использоваться с осторожностью, а лучше не использоваться вовсе.
Но, если вы создали не уникальный контент на сайте, не сходите с ума! Ниже мы рассмотрим, как поисковые системы относятся к дубликату контента, и я поделюсь несколькими советами, которые вы можете применить, чтобы убедиться, что содержание вашего сайта свежее и уникальное.
Чтобы лучше понимать как, например, Google обрабатывает дублированный контент, вам нужно ознакомится с их мануалом https://support.google.com/webmasters/answer/66359?hl=ru Если вы боитесь получить фильтр за дублированный контент, позвольте я вас успокою и приведу цитату из данной справки
Наличие на сайте повторяющегося контента не является основанием для принятия каких-либо мер по отношению к нему. Такие меры применяются только в том случае, если это сделано с целью ввести пользователей в заблуждение или манипулировать результатами поиска.
Вот и все, Google сообщает, что сайт не попадет под фильтр за дублированный контент, если вы не вводите пользователей в заблуждение. Но, если на сайте присутствуют дубли, то нужно разобраться, что это за дубли и решить эту проблему. Существует несколько типов дублированного контента:
- Полный дубль – два разных URL'а имеют одинаковый контент
- Частичный дубль – контент на разных страницах имеет мало отличий друг от друга
- Дубли с других доменов – полный или частичный дубль с другими сайтами (доменами).
Дублированный контент может получится в связи с разными ситуациями. Неправильная структура сайта, которая порождает полные или частичные дубли на разных страницах, лицензионное соглашение выбранной CMS, которое может находиться на разных сайта, шаблонные страницы, такие как публичная оферта, тексты законов и так далее.
Каждая из этих проблем имеет свои пути решения. Прежде чем приступить к решению этой проблемы, рассмотрим последствия наличие дублей страниц для сайта.
Последствия дублированного контента
Если вы разместили на сайте кусок дублированного контента по недосмотру или другим случайным причинам, то поисковые алгоритмы могут просто зафильтровать эту часть текста и отобразят в ТОП лучшие, по их мнению материалы.
Иногда они могут отобразить в ТОП и ваш сайт, даже с не уникальном контентом. Пользователи хотят видеть вверху результатов поиска, сайты с лучшим контентом и поисковые алгоритмы оценивая страницы сайтов, так или иначе могут подмешивать в выдачу страницы состоящие из частично неуникального контента. Какие проблемы могут быть при использовании не уникального контента?
- Краулинговый бюджет. У каждого сайта есть так называемый краулинговый бюджет. Это количество страниц, которые поисковый робот обходит при очередном посещении сайта. При большом количестве дублей контента (фильтра, сортировки в интернет-магазинах, доступные по разным адресам) поисковый алгоритм заходит на эти URL'ы и как только заканчивается краулинговый бюджет, он покидает сайт, из-за большого количества дублей не доиндексировав сайт.
- Потеря ссылочного веса. На внутренних страницах сайта может быть хороший ссылочный вес, но поисковые алгоритмы могут выкинуть из индекса эти страницы.
- Неправильные страницы в выдаче. Никто точно не знает, как работаю поисковые алгоритмы. Поэтому в поисковую выдачу они могут поставить совсем не ту страницу которую следовало бы из пула дубликатов.
Почему появляются дубли страниц?
Существует несколько основных путей появления таких станиц:
1. Параметрические URL
Параметры URL, такие как фильтра, UTM-метки и прочее создают дубль страницы.
Например, адрес этой страницы : https://ex-pl.com/blog/dubli-stranits-na-sajte-kakie-byvayut-dubli-i-kak-ot-nikh-izbavitsya , но она также доступна по следующим адресам:
- https://ex-pl.com/index.php?option=com_content&Itemid=682&catid=11&id=102&lang=ru&view=article;
- https://ex-pl.com/blog/dubli-stranits-na-sajte-kakie-byvayut-dubli-i-kak-ot-nikh-izbavitsya?utm
Однако в первом случае происходит 301 редирект, во-втором, в коде страницы есть тег rel=canonical, но об этом ниже.
2. Домен с www и без www, с http и(или) https
Если ваш сайт доступен по двум адресам "site.ru" и "www.site.ru", один и тот же контент представлен на обоих версиях сайта, т.е. каждая страница сайта имеет полный дубликат. Такая же ситуация и с http:// и https:// если сайт доступен по обоим протоколам, то у каждой страницы также есть свой дубликат.
3. Неуникальный контент
Контент страницы состоит не только из обычного текста или записей в блогах, сюда же можно отнести и графику, и документы в docx, pdf, итд, а также и характеристики и описания продуктов или товаров, если мы говорим о интернет-магазинах. Если множество разных интернет-магазинов продают один и тот же товар и для описания товара используют данные производителя, то такой контент, наверняка, будет использован на множестве других сайтов.
Как найти дубли страниц на сайте?
Существует несколько методов поиска дублей страниц.
Google WebMaster
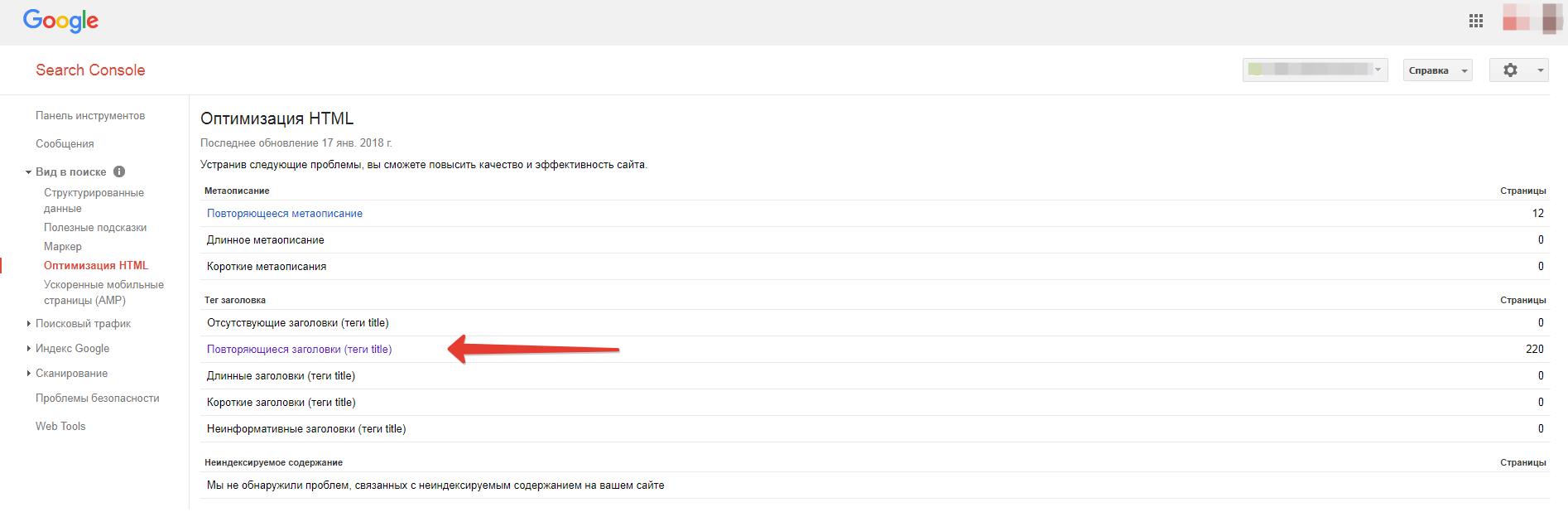
В Google Search Console вы можете посмотреть, у каких страниц есть повторяющиеся заголовки, проверить эти страницы и сделать вывод о том, являются ли эти страницы дублями.
Программа Xenu Link Sleuth

Xenu Link Sleuth – одна из необходимых программ для любого SEO-оптимизатора, которая помогает провести технический аудит сайта и выявить одинаковые заголовки (titles).
Просто просканируйте сайт этой программой, отсортируйте результаты в алфавитном порядке по заголовку и вы увидите одинаковые заголовки. Скорее всего страницы с одинаковыми заголовками являются дубликатами.
Воспользоваться операторами в поисковой системе
В поисковых системах можно произвести поиск не только в глобальной сети, но и на одном отдельно взятом сайте. Например, для того, чтобы в Google найти дубликаты на сайте, нужно сделать специальный запрос, который выглядит следующим образом: site:test.ru -site:test.ru/&.
- site:test.ru – вывод всех проиндексированных страниц
- site:mysite.com/& - вывод страниц участвующих в поиске
Как бороться с дублями страниц на сайте
Наличие не уникального контента на сайте, как в пределах сайта, так и в пределах интернета, не самое полезное явление для поисковых алгоритмов и пользователей сайта. Проще говоря, дублированный контент может негативно сказаться на продвижении сайта, поэтому, желательно от него избавиться. Есть несколько путей решения данной проблемы:
Использование 301 редиректов. Это один из подходов для того, чтобы избавиться от дубликатов. Если один из дублей страниц внутри сайта имеет наибольший ссылочный вес, то решением является сделать 301 редирект из пула дубликатов именно на эту страницу.
Использование файла robots.txt. Еще один выход это использование директив в файле robots.txt, который позволит запретить индексировать дубликаты страниц. В зависимости от ситуации, такое решение может быть не самым лучшим, т.к. директивы в файле robots.txt имеют рекомендательный характер.
Использование rel=“canonical”. Если вы хотите избавиться от дублированного контента, использование rel=“canonical” прекрасный выбор. Данный тег сообщает поисковым алгоритмам, какая страница из пула дубликатов является главной. Этот тег используется в <head></head> и выглядит следующим образом:
<link href="https://ex-pl.com/blog/kak-perejti-na-https-gotovyj-kejs" rel="canonical" />
Хотя дубликаты контента являются проблемой и могут помешать в поисковом продвижении сайта, они не так уж и страшны. Если вы намеренно не пытаетесь манипулировать поисковой выдачей, то поисковые системы, как правило, не наказывают вас. Но, как и говорилось выше, существуют и другие негативные последствия за дублированный контент. Я рекомендую избавиться от дублированного контента, это первый шаг к улучшению позиций сайта.






Сроки и условия
Подписаться
Отчёт